本文共 6041 字,大约阅读时间需要 20 分钟。
来源:李宏毅教程+sakura笔记
实在懒得打字,放代码和手写解析
切片:
对一个三维的数组这样操作,只切掉了第一维的前10000个,后面两个维度不变。

b[::, 0] 这样把第三维切掉~
b[:, 0:2:] 是切第二维,诸此种种
Reshape:重新排布
字面意思。。。。 内元素都不变的哦
损失函数
当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0。
这个是手写识别,二进制就是binary~
返回值
可以直接写return (x_train, x_test),(y_train, y_test) 方便一点
one-hot (每个维度不同的 一般都是one hot吧
这里注意,最开始是比如5,0,9这种的,下面的处理完之后,变成了编码方式。。。。~~~
某个维度变成1的

model部分,还是一样的:
先DNN
加个Dense ,代表是全连接层。
第一行既代表了输入又代表了第一层的单元个数,这里就是,256输入,连接到500,上个500继续连接这500,最后输出10就可以了】
这个意思就是第一维似乎多一点,然后整体5层吧。
输入层一般不算的话就4层

model.add(Dense(input_dim=28 * 28, units=500, activation='relu'))model.add(Dense(units=500, activation='relu'))model.add(Dense(units=500, activation='relu'))model.add(Dense(units=10, activation='softmax'))model.summary()
另外的summary()。。(干嘛的?。。。
最后
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
fit的话也是 ,model.fit(x_train, y_train, batch_size=100, epochs=20),
这样就相当于总共10000个人,每100个人编成一组做广播体操。(这个过程重复了100次,相当于放到100个不同的房间里)
然后epoch相当于总共做了20遍广播体操。
GPU部分别看了看了也会忘的,,,,
最后,可以model.【evaluation或者prediction】来
1 是放入x数据和y数据,y是既定的答案,可以[0] loss [1] Accuracy
2 result = model.predict(x_test) 直接输出结果。
[ CNN加持 ]
x_train = x_train.reshape(x_train.shape[0], 1, 28, 28)
先把原10000 784 维度展开了 变成四维?。。也不是,是有10000个(个数,之前的也是,但是dnn是平的对不对qwq。)大小是28*28*1
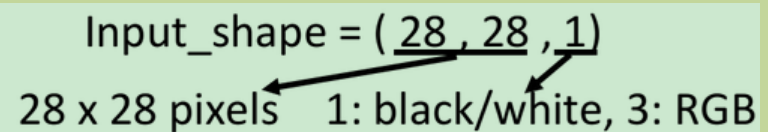
add Convolution2D,参数25代表你有25个filter,参数3,3代表你的filter都是3*3的matrix
MaxPooling2D(2,2) ) 这里参数(2,2)指的是,我们把通过convolution得到的feature map,按照2*2的方式分割成一个个区域,每次选取最大的那个值
本来在DNN里,input是一个由image拉直展开而成的vector,但现在如果是CNN的话,它是会考虑input image的几何空间的,所以不能直接input一个vector,而是要input一个tensor给它(tensor就是高维的vector),这里你要给它一个三维的vector,一个image的长宽各是一维,如果它是彩色的话,RGB就是第三维,所以你要assign一个三维的matrix,这个高维的matrix就叫做tensor
运行报错..... CNN跑不起来qaq。不过先这样吧还是。。。
最后附上代码
以及网址 参考来源
import numpy as npimport pdbfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Activationfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flattenfrom tensorflow.keras.optimizers import SGD, Adam# from tensorflow.keras.utils import np_utilsfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.datasets import mnistimport numpy as npfrom tensorflow.keras import utils as np_utils# categorical_crossentropydef load_mnist_data(number): # the data, shuffled and split between train and test sets (x_train, y_train), (x_test, y_test) = mnist.load_data('E:\ADATA\mnist.npz') x_train = x_train[0:number] y_train = y_train[0:number] x_train = x_train.reshape(number, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') # convert class vectors to binary class matrices print(y_train,y_test.shape) y_train = np_utils.to_categorical(y_train, 10) y_test = np_utils.to_categorical(y_test, 10) print(y_train, y_test.shape) x_train = x_train / 255 x_test = x_test / 255 return (x_train, y_train), (x_test, y_test)if __name__ == '__main__': (x_train, y_train), (x_test, y_test) = load_mnist_data(10000) # do DNN model = Sequential() model.add(Dense(input_dim=28 * 28, units=500, activation='relu')) model.add(Dense(units=500, activation='relu')) model.add(Dense(units=500, activation='relu')) model.add(Dense(units=10, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=100, epochs=20) result_train = model.evaluate(x_train, y_train) print('\nTrain Acc:\n', result_train[1]) result_test = model.evaluate(x_test, y_test) print('\nTest Acc:\n', result_test[1]) # do CNN x_train = x_train.reshape(x_train.shape[0], 1, 28, 28) x_test = x_test.reshape(x_test.shape[0], 1, 28, 28) model2 = Sequential() model2.add(Conv2D(25, (3, 3), input_shape=( 1, 28, 28), data_format='channels_first')) model2.add(MaxPooling2D((2, 2))) model2.add(Conv2D(50, (3, 3))) model2.add(MaxPooling2D((2, 2))) model2.add(Flatten()) model2.add(Dense(units=100, activation='relu')) model2.add(Dense(units=10, activation='softmax')) model2.summary() model2.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model2.fit(x_train, y_train, batch_size=100, epochs=20) result_train = model2.evaluate(x_train, y_train) print('\nTrain CNN Acc:\n', result_train[1]) result_test = model2.evaluate(x_test, y_test) print('\nTest CNN Acc:\n', result_test[1])'''def load_data(): (x_train, y_train), (x_test, y_test) = mnist.load_data('E:\ADATA\mnist.npz') number = 10000 x_train = x_train[0:number] y_train = y_train[0:number] x_train = x_train.reshape(number, 28 * 28) x_test = x_test.reshape(x_test.shape[0], 28 * 28) x_train = x_train.astype('float32') x_test = x_test.astype('float32') # convert class vectors to binary class matrices # y_train = np_utils.to_categorical(y_train, 10) # y_test = np_utils.to_categorical(y_test, 10) y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10) x_train = x_train x_test = x_test # x_test=np.random.normal(x_test) print(x_train.shape, x_test.shape,x_train[545][413]) x_train = x_train / 255 x_test = x_test / 255 return (x_train, y_train), (x_test, y_test)if __name__ == '__main__': # load training data and testing data (x_train, y_train), (x_test, y_test) = load_data() # define network structure model = Sequential() model.add(Dense(input_dim=28*28, units=500, activation='sigmoid')) model.add(Dense(units=500, activation='sigmoid')) model.add(Dense(units=10, activation='softmax')) # set configurations pdb.set_trace() model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # train model model.fit(x_train, y_train, batch_size=100, epochs=20) # evaluate the model and output the accuracy result = model.evaluate(x_test, y_test) print('Test Acc:', result[1])'''
转载地址:http://tluti.baihongyu.com/